Greetings. I am kd-11, graphics developer for rpcs3 with a mid-month update on latest developments on the emulator.
As many are already aware, a lot has been going on lately with the new changes to the RSX (the PS3 GPU) emulation, dubbed vertex rewrite. This change moves a lot of vertex processing duties from the CPU to the GPU where they rightly belong and as a result there are massive performance gains especially with OpenGL but also with Vulkan in geometry heavy scenes.
Background
Most if not all users are probably aware by now, but dedicated graphics cards exist on a physically separate board. This means data has to be moved to and from it through the PCI-E bus which is quite fast. However, while it is high bandwidth, it is also high-latency. That means you cannot just send something over there and expect to get it immediately available for the next draw call. Instead, the GPU has to wait for data to be prepared and then signaled that data is ready for processing before drawing begins. This is a general simplification, but it helps illustrate the point. The RSX on the PS3 doesn’t work the same way however. It has near direct access to the XDR main memory on a PS3 and ‘pulls’ data directly from main memory as though it were local memory. It is somewhat similar to integrated graphics memory in this case. That means data is not ‘pre-packaged’ for transport to the PS3 GPU since the memory is virtually unified from the point of view of the RSX. When using Vulkan, drawing is not scheduled until the whole command queue is flushed mitigating the impact of transfer since data will likely have been uploaded beforehand, but for OpenGL this was a big bottleneck.
The second issue was that the emulator was doing a lot of computation on the CPU on how to read vertex data from main memory, essentially pre-packaging the data into formats easy for GPUs to use. This is a very slow process and also very memory intensive (hence the ‘Working buffer not enough’ crashes). Enabling a debug overlay with the old method shows some games taking up to 200ms to prepare vertex data for one frame (Hellboy: The Science of Evil). This is obviously not optimal. The impact could be lowered by using more threads for vertex processing, but with the number of threads already needed to emulate the PS3’s multi-core processor, it was a problem. Spawning 8+ vertex processing threads reduced the time spent processing vertices, but cost other threads to starve and performance would drop significantly. The solution was to shift the work to the GPU instead and not touch it in any way. Just copy the data block and the GPU could fetch the data it needed for itself, mimicking the behaviour of the real hardware.
Initial tests
The first task was to put this theory to test. I started by writing routines to identify continuous memory used by games to store vertex data and found most use interleaving to help speed up data transfer even on a real ps3. This is good since copying is very easy, boiling down to a single memcpy operation. I quickly got OpenGL to use this method whenever large blocks of data were in use and fired up a test case I had been using for some time to benchmark vertex processing – TNT racers title screen. The scene is very simple but throws up vertices using immediate draws and does over 2000 draws. This was a problem on rpcs3 where OpenGL was stuck at 10fps for a long time. Using the simplified processing, FPS went up to around 17, so the experiment was a success. Vertex upload times went down significantly from about 50ms per frame to under 10ms. However, the change in frame rate was not so impressive, so I had to do some more investigation.
Research and second attempt
After getting feedback from ssshadow that the performance boost was not as expected, I sought to find out how drivers handle memory writes to external PCI-E devices. For this I turned to the mesa open source drivers that I use on my PC and poured through the code. I confirmed the use of write-combined memory to improve throughput and went to work redesigning the rendering pipeline to make effective use of this. The simplified single writes to a small contiguous block already gave a good boost, so I tried reordering where the vertex upload happened to give it some time before the draw call requiring the data was issued. Memory writes were placed very early in the submission chain and other computations moved after this point but before the draw call. This way, the GPU could get the data before it is needed, improving efficiency of the renderer. With this change, I hit a GPU limit at ~25 fps which was 2.5x the initial test result and 10fps over the initial implementation. A driver update later brought the frame rate up to ~28fps but that is where my hardware maxed out.
Vulkan and disappointing performance
After the research was completed, I had a good idea of what to do to maximize throughput on Vulkan as well. I quickly applied the changes to Vulkan and refactored shared code between renderers to make future work easier. I quickly ran the same benchmark on Vulkan expecting 30fps but only got +1 fps gain; from 14 fps to 15fps. After measuring time spent in different parts of the pipeline I found another bottleneck that had been holding back Vulkan for the longest time – Every frame was waiting for the previous frame to complete before beginning rendering. This is not very efficient use of the graphics hardware or the API. Since the baseline framebuffer uses a doublebuffer setup, there are two surfaces to write to. There is no need to wait on previous commands if they write to a different surface. A quick restructure later and the renderer was rewritten to support asynchronous frame processing.
Final results
Combining the two optimizations and running the same benchmark yielded about 24 fps. This was about 10fps higher than the baseline performance provided on master. I fired up another benchmark – Hellboy: The Science of Evil and confirmed fps jumped from 3-5 fps before to 20-30 fps on both OpenGL and Vulkan. As an aside, the memory access behaviour of intel integrated graphics give 40 fps in that TNT racers scene using the new OpenGL backend – almost double the Vulkan performance of a 270x. This shows that things can be better with more optimization.
Before screenshots from Hellboy: The Science of Evil:
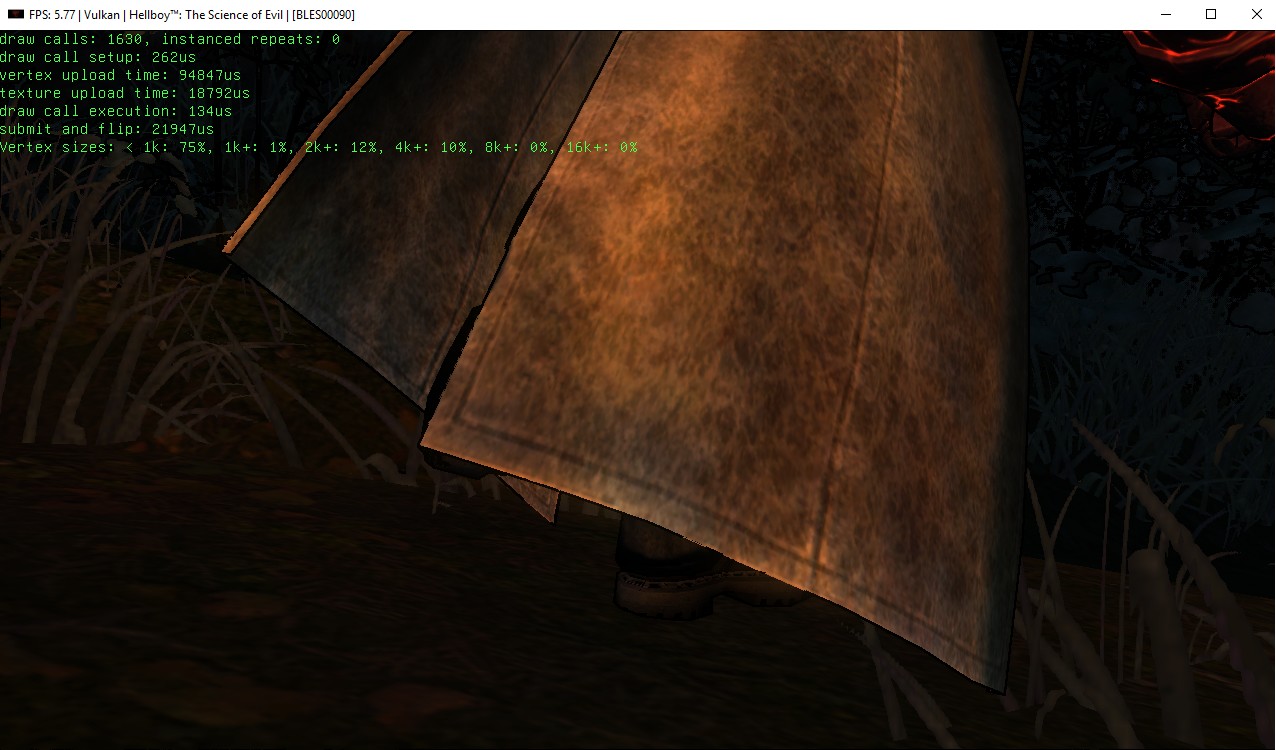 |
 |
 |
After screenshots from Hellboy: The Science of Evil:
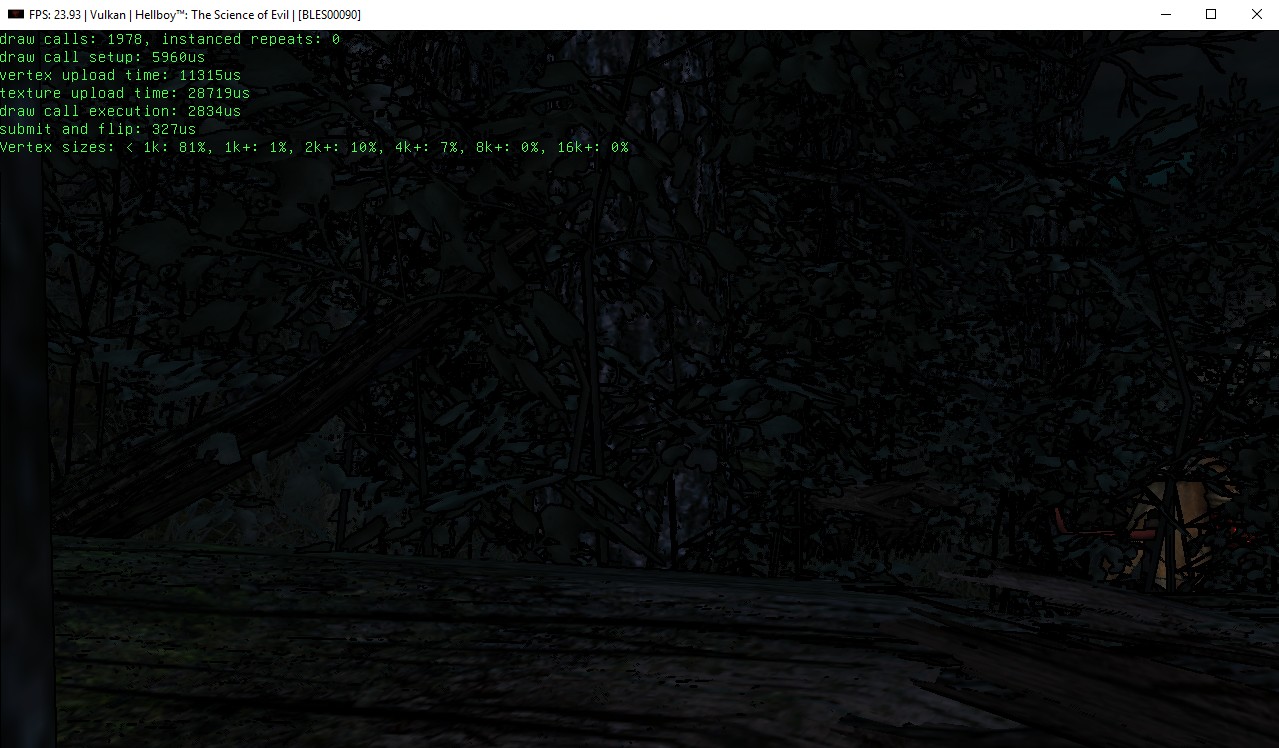 |
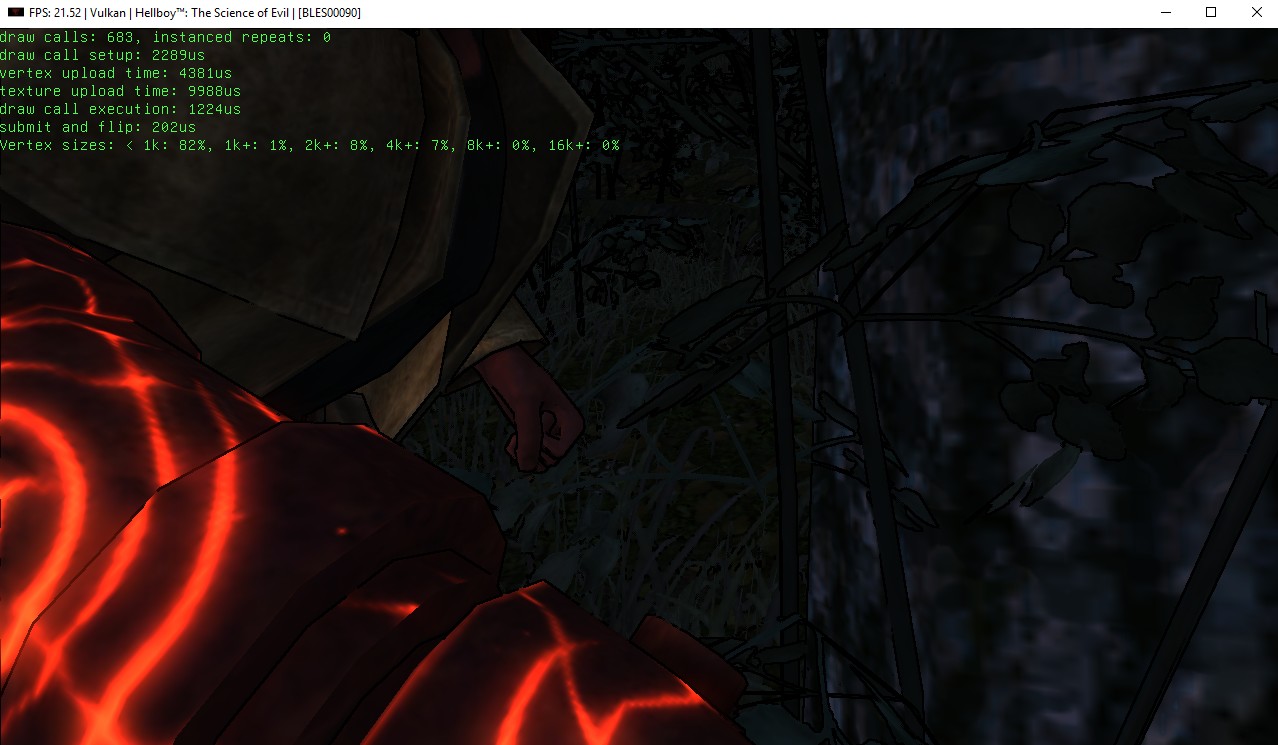 |
Before screenshot from TNT Racers with Vulkan:

After screenshots from TNT Racers. The first two from a dedicated GPU with Vulkan and OpenGL. The last from integrated Intel graphics.
 |
 |
 |
Another side effect of unifying vertex processing and handling things correctly was that many games that did not have any visual output before started working almosy immediately. Most notable cases here are Metal Gear Solid 2 and Metal Gear Solid 3. Shadow of the Colossus also got partially fixed as well as improvements to other games such as Sleeping Dogs and the Yakuza games.
Minor other bugfixes were also added that fixed Ni No Kuni’s flicking graphics when using Vulkan as well as broken depth in that title. Unreal engine 3 games also had broken color in intro cinematics and logos that were fixed as well.
Things were looking good but there was one more problem – shader compilation stutter was making things unbearable.
Shader cache reorgnization
Rpcs3 has always had a JIT shader cache that slowly builds as the emulator runs. It was however very broken on Vulkan causing programs to constantly rebuild. This manifested as microstutter before where the game did not feel smooth although the fps counter showed high fps. With the new more complex shaders, the stutter went from a few milliseconds per shader to several seconds in some cases. Even after fixing the microstutter on Vulkan due to bad key hashing, it still took unbearably long to generate the internal cache into something useful for gameplay, interspersed with minute-long pauses in places. It was quickly apparent that something had to be done. As such I decided to have the shader cache dumped to disk and preloaded when the emulator was started up again. This made significant changes to the feel of games run from within the emulator. A few workarounds were needed to make intel work at all. Its still not working 100% but improvements will be coming.
Bugs and technical issues
While the changeset does improve the core rendering pipeline a lot with the new systems, it brings with it new baggage. First is the aforementioned increase in shader compilation times. The second more serious issue is more relevant to nvidia users – high memory usage when the number of precompiled shaders rises. This issue was brought to my attention by a user on discord who mentioned that Cemu works the same way and that nvidia users experience the same problem with memory usage going up very high. On rpcs3, this means you can see the emulator consume 5+ GB of RAM when compiling the shader cache. An interim solution for those with lower RAM would be to clean the shader cache periodically until we find a suitable workaround. More information can be found here.
Lastly, intel drivers (at least on windows) have buggy glsl generation. I have a workaround in place specific to intel but it wont fix all problems on that platform. More work is certainly needed.
What does this mean?
First, it means OpenGL is now within striking distance of Vulkan in terms of performance and faster in some cases. Vulkan however suffers more from the first-time shader compilation stutter. This will be improved in the near future, but for now, you may want to give OpenGL a try if the stutter is too distracting or avoid the new nightly builds for now. Overall Vulkan is still faster now with the reworked framework. I have seen suggestions about disabling the shader cache – that wont help with the stutter since its caused by the linking step that is done by the drivers. I would ask those negatively affected to be a little more patient as we work to resolve the issues.
Closing Words
If you want to help out and make RPCS3 progress even faster you can check out the Patreon page here. Right now we are coming closer and closer to the $3000 goal of having me, kd-11, work on RPCS3 full time which would greatly increase the rate of progress in the future.
